[Raft] Summary: The Knowledge Points In Raft
TL; DR
这是一篇关于 Raft 知识点总结的博客。总结的不全,尤其是 Snapshot 那块。如果有理解错误或者笔误的地方请联系我!
主要参考:
- 论文:https://github.com/ongardie/dissertation/blob/master/stanford.pdf
- ETCD 的文档:https://github.com/etcd-io/etcd/blob/main/raft/README.md
Knowledge Points
[C3] 持久化的状态有哪些,以及为什么
- log[]
- currentTerm
- votedFor
这三个属性都保证:一个 Term 只能给一个 Candiate 投票。
[C3] 为什么不持久化 CommitIndex
如果持久化了上述三个属性,CommitIndex 就不是必须持久化的属性。重启后设置为 0 也没关系。
[C3] 如何保证不 reapply log
持久化 AppliedIndex。
[C3] 如果 Server 的持久化数据丢了怎么办
如果丢了的 Server 数目小于大多数,可以用新的身份重新加入集群。如果大于等于,就可能丢数据。所以必须承认还是有丢数据的可能。
[C3] 被投票要满足哪些条件
- 第一种情况:Receiver 的任期等于 Sender 的任期,并且 Receiver 给 Sender 投过票,并且 Receiver 的 Log 小于等于 Sender 的 Log。
- 第二种情况:Receiver 的任期小于 Sender 的任期,并且 Receiver 在此任期没有投过票,并且 Receiver 的 Log 小于等于 Sender 的 Log。
日志判断大小的依据:
- Log 的 Term 大,日志大
- Log Term 相同的情况下,Index 越高越大
[C3] Leader 为什么不能提交之前任期的日志
当之前任期的日志就算被 replica 了大多数份了以后依然有可能被覆盖。
如下图所示,是论文中的具体例子。
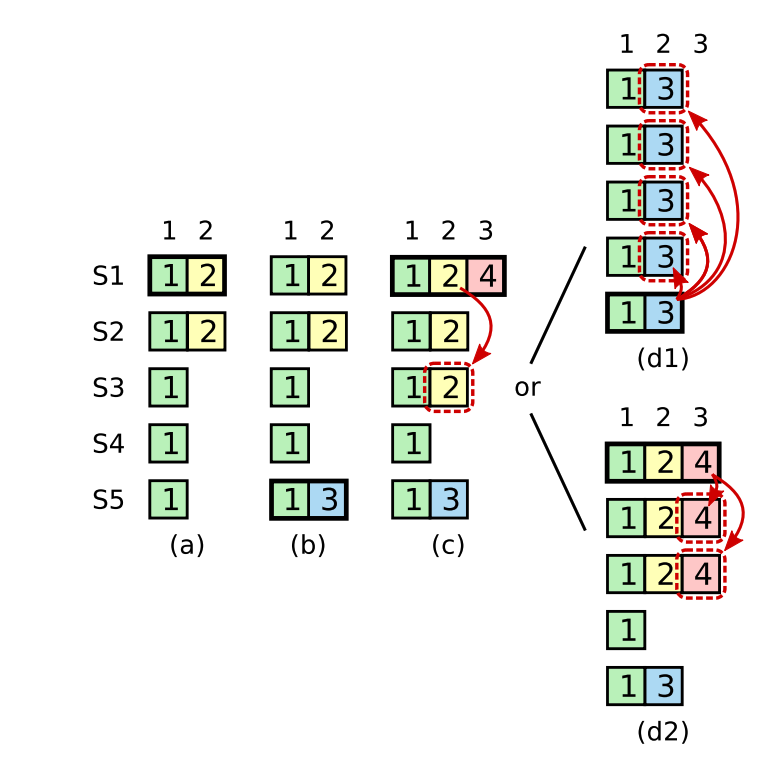
(a) 有 5 个 Server,S1 是 Term=2 的 Leader,现在 5 个 Server 都有 (Term=1, Index=1) 的日志。并且 S2 同步了 S1 的日志 (Term=2, Index=2)。
(b) S1 发生了崩溃,S5 当上了 Term=3 的 Leader(收到 S3,S4 的投票)。并且 S5 写入了 (Term=3, Index=2) 的日志。
(c) S5 还没来得及同步,发生了崩溃。S1 当上了 Term=4 的 Leader(收到 S2,S3 的投票),并且给 S2,S3 同步了 (Term=2, Index=2) 的日志。此时该日志已经被大多数 Replica 了。
(d1) S1 发生了崩溃,S5 当上了 Term=5 的 Leader(收到 S3,S4 的投票),在发生同步的时候把 (Term=2, Index=2) 日志覆盖了。也就是说,被 Replica 了大多数份了以后依然有可能被覆盖
也就是说,不能按日志被 Replica 的数目来设置 Commit Index。Leader 只能提交自己任期的日志。
[C3] 系统中有哪些对时间的依赖
虽然任期和日志都是 和时间无关的,但是这个系统想要稳定的持续下去,不可避免的依赖真实的系统时间。
broadcastTime << electionTimeout << MTBF
- << 表示:表达式右值要至少大于表达式左值一个数量级。
- MTBF 表示:Mean Time Between Failures。
其中 broadcastTime 其实指的是 RPC 的平均传播时间,其中包括请求在网络上的传播以及数据持久化的时间。broadcastTime 和 MTBF 是底层系统的时间,Raft 需要自己设置 electionTimeout。
具体含义如下:
- broadcast time << electionTimeout
选举的超时时间要至少比传播时间大一个数量级,不然传播还没结束,又开始新的选举了。
- electionTimeout << MTBF
系统崩溃的时间至少要比选举的超时时间大一个数量级,不然选举还没完成,系统又崩溃了。
[C3] Leader Transefer 全过程
Leader Server 不可避免的可能需要将 Leader 权限主动转移到其他 Server。所以在协议中涉及 Leader Transefer 。具体步骤如下:
- Leader Server 接受到 Leader Transefer 以后,不再接受后面的 Client 的请求。
- 向目标 Server 发送日志,直到目标 Server 和自己的日志一样新。
- 给目标 Server 发送 Timeout 的请求。
这样目标 Server 就会立即选举超时,立即成为 Candidate,拥有比 Leader Server 更高的 Term。Leader Server 接受到目标 Server 的 RequestVote 的时候就会退化成 Follower。这样就完成了 Leader Transefer。
当然目标 Server 也可能挂掉,所以为了保持可用性(不可用的时间 <= 选举时间),当 Leader Server 在一个选举时间内,发现没有完成 Leader Transefer,会停掉 Leader Transefer,再次接受 Client 的请求。
[C4] Cluster Membership Changes 全过程
分布式系统中成员的变更是不可避免的。如何在成员变更的时候保证顺序一致性,又是一个新的挑战。在 Raft 中,推荐使用单步变更。
单步变更指的是每次只添加或者删除一个 Server。使用单步变更的原因在于:不论是添加还是删除,旧集群的 majority 和新集群的 majority 一定会发生重叠。这样就保证了 Cluster Membership Changes 的安全性。
- Leader Server 收到 Cluster Membership Changes Request
- 等待上一次 Cluster Membership Changes 结束
- 将 Cluster Membership Changes Append 到日志中
- 更改当前 Leader 的 Membership(不需要 commit)
- 将日志同步给其他 Server
- 当其他 Server Append 到 log 后,修改自己的 Membership
- 当这个 Cluster Membership Changes 提交以后,本次 Membership Changes 结束
[C4] 为什么加入新的 Node 会有可用性的问题并如何解决
以下两种情况都会引入集群可用性问题:
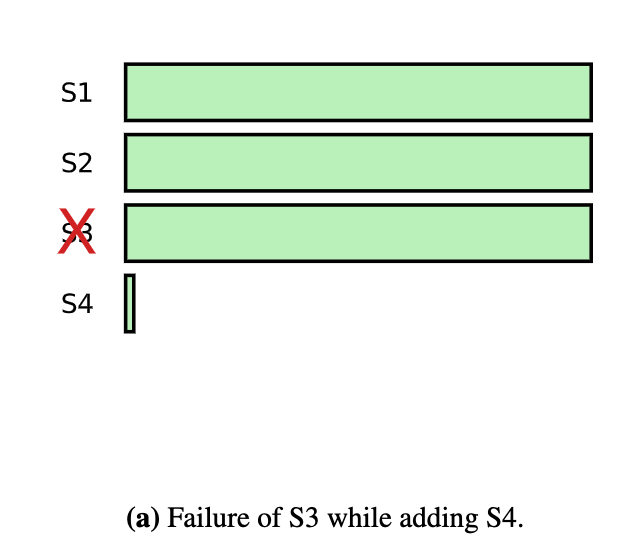
- 当加入新的 Node S4 以后,由于 S4 没有任何日志,如果 S3 挂掉了,集群中的请求没办法很快达到大多数,这样就新增了可用性的问题
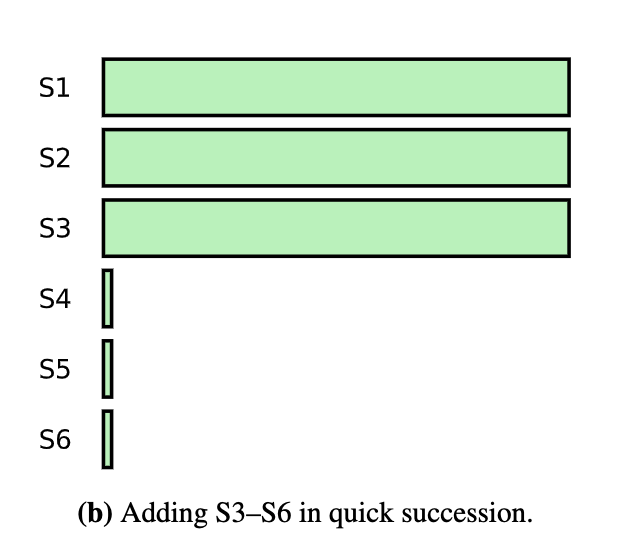
- 当快速加入新的 Server 以后,由于 S4,S5,S6 没有日志,集群中的请求没办法很快达到大多数,这样同样新增了可用性的问题
解决办法如下:
加入新 Node 的时候不直接参与投票,而是以一种 Leaner 的身份加入集群,然后在合适的时候(日志同步的差不多了)再转换身份可以参与投票。
选择合适的时候的方法如下:
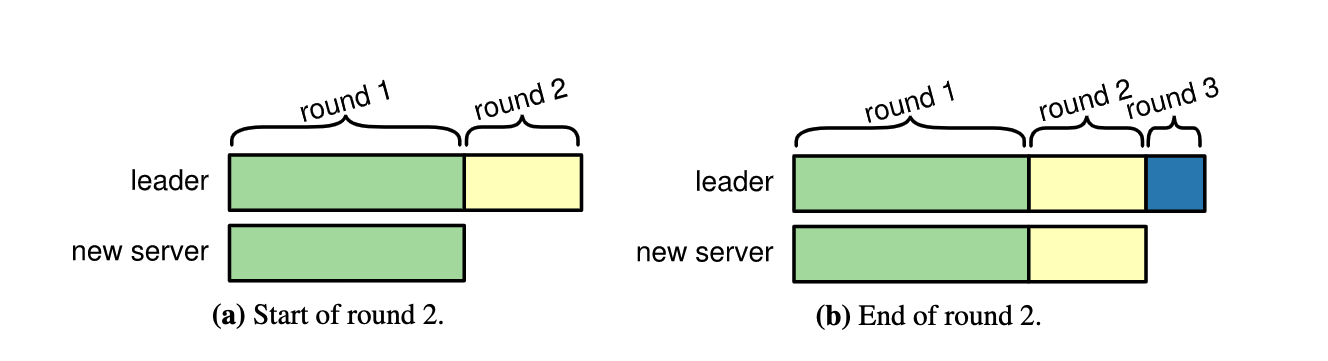
如图所示,日志同步其实是多个 round 同步的过程。原因是在同步的过程中也会产生新的日志。只要上一个 round 的同步时间小于选举时间就是一个把新 Node 加入集群参与投票的合适时间。
[C4] 删除的 Node 是 Leader 怎么办
由于删除的 Node 是 Leader,所以会导致不可用一段时间。Raft 中提出了这样的删除 Leader 的一种方法:
- Leader 收到删除自己的 Request 以后,还做 Leader 同步一段时间
- 并且在计算 commit 的时候不算自己的票
- 一旦 commit,自己 step down
举一个极端的例子来分析这样是可行的。假设集群中只存在两个 Server:S1 和 S2,并且 S1 是 Leader。现在要删除 S1。流程如下:
- S1 收到删除自己的 Request 以后,从成员中将自己删除,但是还做 Leader 给 S2 同步
- S2 收到 S1 的请求以后,从成员中将 S1 删除,发送消息给 S1
- S1 收到 S2 的 Response 以后,此时 1 为大多数,满足大多数,提交,S1 step down
- S2 没收到 S1 的 Heartbeat,S2 超时,自己做 Leader
[C4] 为什么引入 Pre-Vote
当删除的 Server 不是 Leader 的时候,那个 Server 将不再收到来自 Leader 的心跳。所以会自增 Term 给其他的 Server 发送 RequestVote。导致 Leader 收到比自己大的 Term,变成 Follower。这样会影响可用性。
解决这种情况有一个朴素的方案:Pre-Vote。
就是在发起 RequestVote 之前,先预投票一轮,看自己能不能当上 Leader(任期大不大,日志够不够新),如果不能也就没有必要发送 RequestVote 了。
[C4] 什么情况下 Pre-Vote 没有作用以及怎么解决
在删除 Node 的一些情况下,Pre-Vote 依然没有作用,依然会扰乱当前的集群。例子如下:
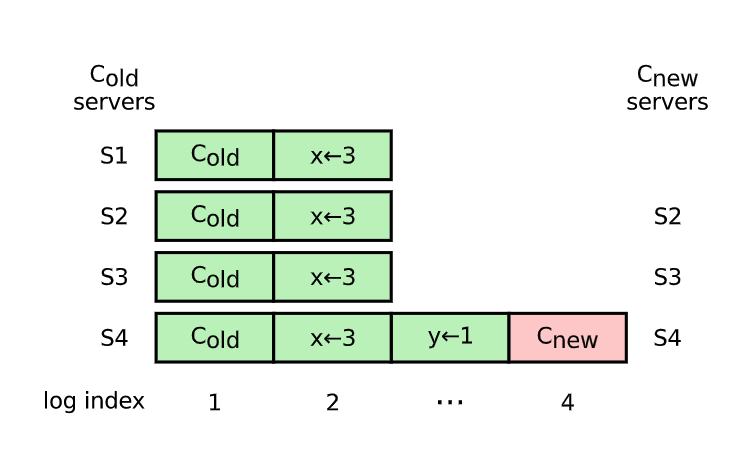
当 S4 是 Leader 要删除 S1 的时候。当 S4 把 Index 为 4 的日志 append 到日志以后,就不再给 S1 发送消息了。此时 S1 可能正好选举超时,由于 S2,S3 的日志和 S1 一样新。所以 S1 可能当上 Leader,这样就扰乱了当前的集群。
解决办法如下:
if a server receives a RequestVote request within the minimum election timeout of hearing from a current leader, it does not update its term or grant its vote. It can either drop the request, reply with a vote denial, or delay the request;
如果一个 Server 在收到 Leader 的心跳之后的最小选举超时时间内收到了更新 term 或者请求投票的请求,那么这个 Server 可以选择拒绝这个请求。
这样就保证了一个高 Term 请求扰乱当前集群,降低可用性。但是这样和之前提到了 Leader Transfer 有矛盾。做法应该是在 Leader Transfer 之后的 Request Vote 中加上一个特殊的字段,用来表示就是来扰乱集群的。
[C5] 为什么需要 Snapshot
- 减少 Raft Log 占用空间
- 减少日志从 Leader 到落后太多的 Follower 复制的开销
[C5] Snapshot 要持久化哪些状态
- 这个 Snapshot 最后日志的 Index
- 这个 Snapshot 最后日志的 Term
- 这个 Snapshot 本身
[C5] 什么时候 Snapshot
在 Raft 实现中,每一个 Server 都可以 Snapshot。这样降低了只有 Leader Snapshot 然后分发给其他 Server 的各种开销。
选择一个合适的时机去做 Snapshot 是一件重要的事情。论文中提供了判断合适时机的方法:
Servers take a snapshot once the size of the log exceeds the size of the previous snapshot times a configurable expansion factor. The expansion factor trades off disk bandwidth for space utilization.
就是设置一个阈值 a,当可以做 Snapshot 的 Log 的 size 是 Snapshot 的 a 倍的时候就可以选择做 Snapshot 了。
[C5] 如何减轻 Snapshot 对 Client Performance 的影响
Snapshot 会影响 Bandwidth,所以会影响写入性能,论文中提供了优化的思路:
- AppendEntries 使用的物理设备和 Snapshot 使用的物理设备不一致
- 在 Minority 的 Server 上做 Snapshot
[C6] Client 如何把请求发送给 Leader
如果非 Leader 收到了 Client 的请求,返回知道的 Leader 的信息。这样的好处就是之后的请求都会走 Leader,速度快
或者如果非 Leader 收到 Client 的请求,可以作为访问 Leader 的 Proxy。这样的好处在于只读情况下,可以通过 readIndex 这样的方法降低 Leader 的负载
对于 Minority 的 Leader 来说,一旦在选举超时时间内没有成功给 Majority 的 server 发送心跳,自己回退成 Follower。
[C6] 为什么需要 no-op Entry
因为 Leader 不能提交不是自己任期的日志,如果新 Leader 一直没有收到 Client 的请求,那么一直没有该任期的日志就会一直不能更新 commitIndex。No-op Entry 就是一个该任期的没有任何操作的日志,用来后续更新 commitIndex。
[C6] Client 注册过程
由于 Client 与 Server 的交互消息存在丢失的风险,Client 的一个 Command 可能被 Apply 多次。原因是 Client 的 Response 因为网络问题 Client 没有收到,导致 Client Retry 。
为了避免 Server 的 State Machine Apply 一个 Command 多次,Server 必须识别出重复的 Request。
为了实现这一点,Server 给每一个 Client 维护了一个 Session。首先是 Client 注册过程,为了识别每一个 Client:

重要:
- 等这个命令提交以后在 State Machine 中存储这个 Clinet 的 Session。
- 返回一个 Unique Identifier。
[C6] 线性一致性 VS 顺序一致性
我的理解是这样的:
「线性一致性」保证了在事务 A 提交之后开始的事务一定能读到事务 A 的结果,每个事务是一个接着一个执行的。而「顺序一致性」是多个事务的结果可以用一个事务接着一个事务执行的结果来解释。而具体的两个事务之间没有一定的保证。
举一个满足顺序一致性但是不满足线性一致性的例子:

图中横轴代表时间,纵轴代表不同的事务。W(x, 2) 表示向 x 中写入 2。R(x, 2) 表示从 x 中读出 2。一个事务的开始时间是这个事务的最左边事件的左边框结束时间是最右边事务的最右边框。
图中事务 C 读到 X = 2 明显不满足线性一致性。但是这四个事务可以满足顺序一致性(图中下面的 Reordered)。
这是我自己的理解!如果有不对的地方,请向我指出!谢谢
文章中好像只要保证每次读到的 commitIndex 保持单调就行了。
[C6] Client 读过程
有了之前线性一致性 VS 顺序一致性,在我看来,在 Raft 中每一次读或者每一次写,就是一个事务。为了实现 「线性一致性」的读,有一个朴素的想法就是把读也写入 Raft Log 中。这样 apply 的时候一定能被到之前提交的写。
但是论文中提出了一个优化思路:readIndex。本质就是:得到当前最大的 CommitIndex,然后假设读就是紧跟这个 Index 后面。然后等待 State Machine 至少 Apply Index 到 readIndex 再返回。
这样同样满足「线性一致性」的。在这个时间点之前提交的都能读到。不会读到旧数据。

重要:
- Leader 获得 readIndex 办法就是给所有的 Server 发送心跳,确保自己是 Leader,如果超过选举超时时间还没收到大多数的 response,自己回退成 Follower。
- Follower 做 Proxy 的时候,向 Leader 询问 readIndex,然后 Leader 再做一遍上述操作。
[C6] ReadIndex <= ApplyIndex?
文章中说的都是 At Least。所以 ReadIndex <= ApplyIndex 就可以实现线性一致性了。不一定要等于。
[C6] Client 写过程
为了防止重复执行,Server State Machine 存储了 Client 执行过的 Command 的结果。每一个 Command 有一个 SeqNumber。用来识别重复的 Command。

重点:
- 在 Apply 的时候如果 clientID 存不存在或者 Session 是否过期。如果没过期并且 State Machine 存储了 SeqNumber 的结果,直接返回。否则 apply 以后存储结果再返回。
- 判断 Session 过期的办法:小于存储的 Client 的最小 SeqNumber。
[C6] Client Session 驱逐
由于不能无限存储一个 Client 的 Session。所以需要选择 Session 去驱逐。并且驱逐是要写进日志的。得所有 Server 一起同步。
当驱逐这个 Client 的 Session 的时候不能简单的直接创建一个新的 Unique Identifier。这样还是有重复执行的风险。
所以对于 State Machine 来说需要判断是一个新的 Client,还是这个 Client 的 SeqNumebr 被过期清理了。如果是过期清理,Client 就得考虑是新增 SeqNumber 去执行新的请求还是直接 Crash。
[C6] 使用时间机制的读优化
readIndex 的读优化不依赖真实的时间。如果所有的 Server 的时间是同步的,那么可以用 Lease 优化(但是真实的系统很难保证)。
之前提到过如果 Leader 发送心跳给其他 Server 了,这些 Server 都会保持小于选举超时的时间不会给其他 Server 投票。这样就保证了:如果此 Leader 刚给其他 Server 发送过心跳,那么就会有这么一段时间,Leader 就是 Leader 不会变成别人。那确定最大 commitIndex 的时候也不用重新发送心跳了,这就是 Lease 优化。
如果 Server 间的时间不同步,依然存在读旧数据的风险。但是,即使时间不同步,也有办法实现一致性读。Server 在返回的每个请求上带上 index,Client 维护自己见过最新的 index,Client 发送请求的时候带上这个 index。如果 Server 见到请求中的 index 比自己的 ApplyIndex 大就拒绝这个请求。
[C10] 写优化
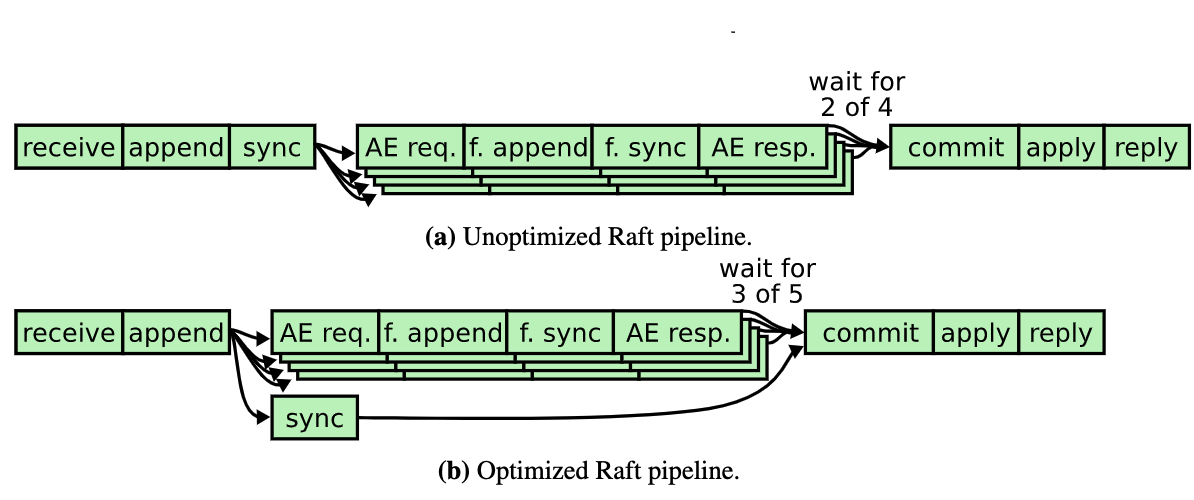
简单来说就是把 Sync 磁盘与和 Follower 同步日志并行处理。
[C10] Batching and pipelining 优化
Batching:Leader 向 Follower 同步的时候发送多个 Entry。
Pipelining:Leader 每次发送 AppendEntries 不管成功与否直接更新 NextIndex,这样在正常的情况下,Follower 可以在 Sync 的上一次 AppendEntries 的同时,从网络中接收新的 AppendEntries。